Finding 4 Lost Orders Inside a Broken WooCommerce Sync
A NZ food manufacturer's WooCommerce orders had been silently failing to reach their ERP for months. 3,500 orders were re-fetched every hour. Four real orders had never shipped. We traced it to a single typo and rebuilt the sync properly.
Background
A New Zealand food manufacturer runs an online store on WooCommerce and their accounting, inventory, and production on NexWave, an ERP platform we maintain for NZ/AU businesses. Orders flow from the website to the ERP via a scheduled background sync. When it works, the supply chain team sees new orders, picks them, and ships them. When it does not work, orders quietly do not arrive, and staff only notice when a customer calls asking where their parcel is.
In early 2026 the customer raised a support ticket: they believed some orders were not making it into the ERP. Nothing was obviously broken. The sync was running. No errors in the logs. But the feeling, driven by a few customer complaints over a period of months, was that something was wrong.
The Challenge
The suspicion was vague. The sync was running every hour. Logs showed it processing orders. There were no exceptions in the error logs. Any straightforward review would have said: “it’s working, the customer is mistaken.”
The technical challenge broke down into three parts:
- Identify the actual failure. Is the sync broken? Partially broken? Correctly rejecting orders that should be rejected? Without a reproducible case we had to treat this as a forensic exercise, not a bug report.
- Find any missing orders. If the sync was quietly losing orders, how many, which ones, and since when? This required reconciling two systems with different schemas and different views of “an order.”
- Fix the underlying issue in a way that makes silent failure impossible next time. Not just patch the symptom, but change the architecture so that a similar problem in the future produces an alert, not a phantom.
The Root Cause: A Doctype That Did Not Exist
The sync maintained a timestamp, the last successful sync date, used to decide which WooCommerce orders to pull on each run. Pull orders modified since last_sync_date, then update last_sync_date to the current time, then exit. Standard incremental-sync pattern.
The bug was in one line of code. The sync was writing last_sync_date to a doctype that did not exist: WooCommerce Settings. The actual doctype was WooCommerce Integration Settings. The write was silently failing, Frappe’s db_set tolerates missing doctypes without raising, and the timestamp was never advancing.
Every hour, the sync would read the initial last_sync_date (the date the integration was first enabled, back in September 2025), pull every order created or modified since then (3,500+ orders), attempt to process all of them, and hit a timeout before getting through the whole list. Then it would run again. And again. And again. For months.
Because of the timeout, different subsets of orders were processed on different runs. Most orders eventually made it through on one run or another. A few unlucky ones, orders that initially failed payment (Stripe card decline), were later marked paid by the customer on a retry, but sat deep in the sync queue, were never processed because the sync timed out before reaching them.
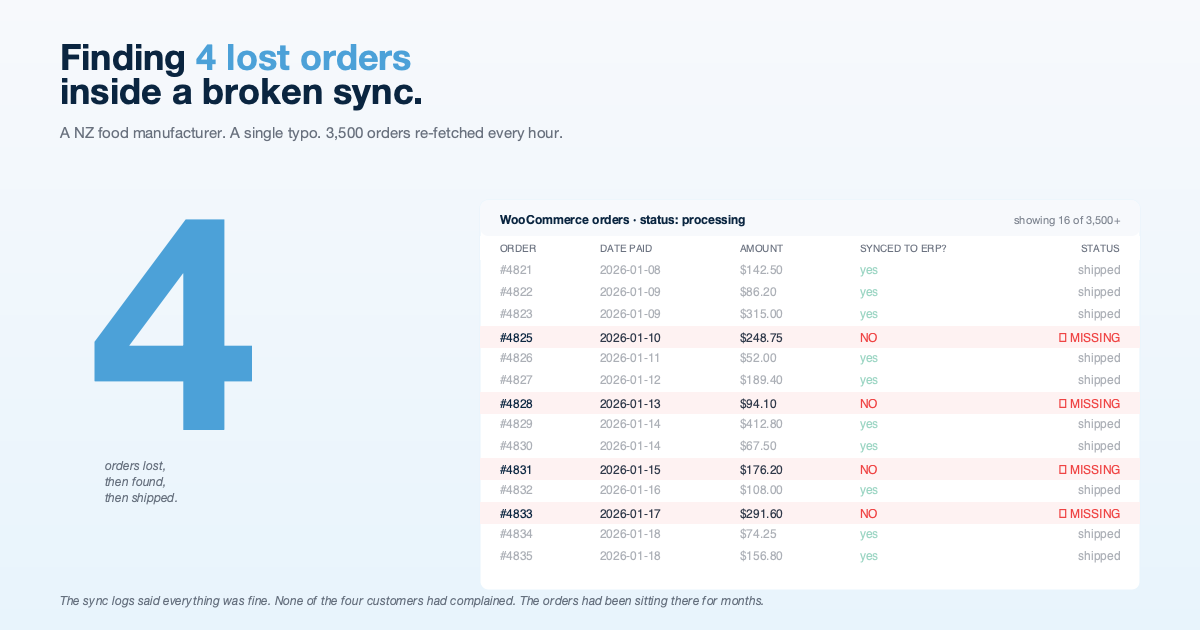
Four orders had been sitting in that purgatory. They were paid, ready to ship, and had never appeared in the ERP.
How We Found Them
Once the root cause was clear, identifying the missing orders was a matter of diffing two systems:
- From WooCommerce, pull every order with status
processing(paid, not yet shipped). - From the ERP, pull every Sales Order with a matching WooCommerce ID.
- Find WooCommerce orders with no corresponding Sales Order.
The diff returned four orders. Cross-referenced against their date_paid timestamps, every one was a “retry”, a customer whose first payment attempt had declined, who came back later and successfully paid. The sync had never caught up to them.
We pulled the order details, loaded them into the ERP manually with the correct Sales Order numbers, flagged them to the supply chain team, and arranged for shipping. The customers, none of whom had actually complained, received their orders within 48 hours.
The Rebuild
Finding the bug is half the work. The other half is making sure the same class of bug cannot happen again.
From Fire-and-Forget to Synchronous with Failure Tracking
The original sync was a loop that enqueued each order for processing in a separate background job. Fire each job, move to the next order, do not wait. This gave the sync the illusion of progress but hid the real failure signal: we never knew which orders had actually synced and which had crashed in their background worker.
We switched to synchronous execution within the sync run. Each order is processed before the next one starts. If a job fails, it is logged with structured context (order ID, failure reason, stack trace) and the sync continues to the next order. At the end of the run, we know exactly how many succeeded and how many failed.
Conditional Sync-Date Advancement
The timestamp now only advances if there were no “real” failures in the run. Transient errors (temporary API failures, network blips) do not count, we retry them. But if an order was structurally broken and could not be processed, the timestamp stays put and the sync will try that order again on the next run.
A Safety Buffer on the Sync Date
Rather than setting last_sync_date = now, we set it to now - N hours. The next run then re-checks the last N hours of orders. Almost always they will be no-ops (nothing new), but in the edge case where an order was created inside the window between our API call and our timestamp update, the safety buffer catches it on the next run. Belt and braces.
We started at 2 hours and bumped it to 6 hours a week later after watching a handful of edge cases in production where very-new orders were still settling when the next sync tick ran. The cost of the longer window is nil (no-op for most orders), and the safety margin is worth far more than the marginal duplicate-check work.
Structured Logging
Every exception handler that used to silently swallow errors now logs them with enough context that a future engineer can reconstruct what happened. The specific kind of failure that caused this, writing to a non-existent doctype, would now produce a warning log pointing at the specific call that failed.
We also added warning logs to the silent exception fallbacks in the status mapping helpers. Previously, a payment status the sync did not recognise would be mapped to “unknown” without leaving a trace. Now it logs, so the team sees that WooCommerce is returning a status the integration does not handle yet.
The Results
- Four lost orders identified and fulfilled. None of the four customers had raised a complaint, which is both a relief and a reminder that silent integration failures do not always produce screaming users.
- 3,500 orders no longer re-processed every hour. The sync now processes, on average, a handful of new orders per run. Database load dropped. API throughput dropped. Worker timeouts stopped.
- Zero orders lost since the rebuild. Every subsequent run has processed every new order successfully.
- A clear audit trail. Every sync run now writes a structured log. If something goes wrong, someone will see it.
What We Learned (Or Had Reinforced)
- “The sync is running” is not the same as “the sync is working.” The original code produced all the outputs of a working sync, log lines, database writes, background jobs enqueued, while silently accomplishing nothing useful.
- Silent exception handlers are almost always wrong. Every catch block should either handle the error specifically, or log it loudly. A third option, swallow and continue, is a bug waiting to surface months later.
- Firing background jobs without tracking them is not decoupling, it is pretending. You traded a crashing sync for a sync that cannot tell you what it did.
- Incremental sync timestamps need a safety buffer. A multi-hour re-check costs almost nothing and prevents a whole class of race conditions.
- Doctype references are a typed interface, but they are string-typed. Frappe’s
db_settolerates missing doctypes. Our validation did not catch this because it was a runtime write. Integration tests against a real bench would have. They do now.
Technology Stack
- WooCommerce as the e-commerce platform
- Frappe v15 as the underlying framework for NexWave
- Python for the sync orchestration and order mapping
- MySQL for transactional storage
- Structured logging for operational visibility
Code References
The fix was upstreamed to our fork of woocommerce_fusion. The full change is open source:
- PR #6 — Fix wc_last_sync_date advancement in bulk sync tasks — the umbrella PR covering the doctype correction, synchronous execution switch, and safety buffer.
- Main fix commit — corrects the
wc_last_sync_dateadvancement in bulk sync tasks. - Safety buffer tuning — follow-up that increased the buffer from 2 to 6 hours after watching it in production.
Key files worth reading:
woocommerce_fusion/tasks/sync_items.py— item sync switched to synchronous execution with conditional date advancement.woocommerce_fusion/tasks/sync_sales_orders.py— sales order sync using the same pattern.woocommerce_fusion/utils/__init__.py— theWC_SYNC_SAFETY_BUFFER_HOURSconstant.woocommerce_fusion/utils/logger.py— the structured logger utility that makes the next silent failure impossible to miss.
Why This Case Study Exists
Most case studies showcase shiny new builds. This one showcases debugging a months-old silent failure in a piece of plumbing. The reason it is here is that plumbing matters. When an integration fails quietly, the cost is not immediate, it is the slow erosion of trust in the system, the growing manual workaround, the customer complaints you never hear about because the customer gave up and went to a competitor.
The right response to a vague suspicion from a customer who knows their business well is to take it seriously. We did, and it turned out to be a single-character typo hiding 3,500 unnecessary database reads an hour and four unshipped orders.
Conclusion
Integration debugging is unglamorous work that needs the same rigour as green-field engineering. The difference between a “working” integration and a reliable one is invisible until something breaks, by which point the cost of the difference is enormous.
HighFlyer specialises in this sort of work. If your integrations are running but you have a nagging feeling that something might be wrong, it probably is, and we would be glad to help find it.
Got an integration that is “working” but something feels off? Get in touch, we are good at this.
Project Details
Client:
Food Manufacturer (NZ)
Industry:
Food & Beverage Manufacturing
Key Metrics:
4
Lost orders identified and recovered
3,500+
Orders being re-fetched every hour
1
Typo that caused it all
0
Orders lost since the rebuild
Achievements:
- Traced a months-old silent integration failure to a single incorrect doctype reference
- Identified 4 missing orders by cross-referencing WooCommerce against the ERP
- Rebuilt sync logic from fire-and-forget to synchronous with failure tracking
- Added conditional sync-date advancement and a safety buffer to prevent recurrence
- Added structured logging so the next failure will be visible, not silent
Ready to Transform Your Business?
Let's discuss how our expertise can help you achieve similar results.
Contact Us Today or Book a MeetingExplore More Case Studies
Discover how we've helped other organisations across various industries achieve their strategic objectives.