
The Invisible Work: What Separates a Six-Month Software Project From a Six-Year One
This is a post about the work on a software project that does not produce a screenshot. It is the work that decides whether the project is worth anything in year two.
The short version. Software projects are sold on the visible work: screens, features, demos. The invisible work (tests, careful data migrations, useful error messages, audit trails, things that survive a bad night) is what decides whether the project still works in eighteen months. Teams that skip it ship faster and lose their customers slower. Teams that invest in it ship slightly slower and still have customers in year five. The difference is not quality-for-its-own-sake. It is the cost, three years later, of being called at 11pm because something you built has just corrupted somebody’s books.
The Foundation Problem
A builder does not get paid extra for the foundations. The client sees the finished walls, the paint colour, the doors. The foundations sat in the ground three months ago and are now covered by concrete. If you asked the builder to skip them, you might save 15% on the build, but you would not be in the building for very long.
Software has the same problem with a different shape. The visible work is the interface, the features, the dashboards. The invisible work is everything that decides whether the visible work keeps working when things change. And clients, unless they have been burned before, often do not know the invisible work is there to ask about.
We have been doing this long enough that we can tell, usually within an hour of looking at a system, whether its previous team was doing the invisible work or not. Not from the obvious code quality, but from the secondary signals: do the automated checks run? Do they check anything useful? Can a data change be safely undone? Is there a record of who did what, when, and to which records? When errors happen, do they produce a message a future engineer could actually act on? If the answer to more than one of these is no, the cost of maintaining the system for the next year is going to be several multiples of what it should be.
What the Invisible Work Looks Like
Tests
A test, in software, is not a checkbox. It is a sentence that says, “this is what I believe this part of the system does, and here is how we can verify it.” The invisible work is writing tests for the things that actually matter: that a submitted invoice actually reserves stock; that a cancelled document actually reverses the accounting entries; that a credit note actually decrements the right account.
The tests that catch real bugs are rarely the ones that test the happy path. They are the ones that test the weird corners. What if the user cancels the invoice while the system is in the middle of pushing it elsewhere? What if two users submit the same quote at the same time? What if a data migration runs on a system where a previous attempt only got halfway through?
When we rebuilt a GST inclusive pricing feature recently, it shipped with 53 different automated checks. Most of them were about the edge cases: amendments to invoices that had already been sent, multi-currency invoices, manual GST overrides, cleaning up records left orphaned by other failures, undoing the full life of a transaction. You could test the feature “works” in four cases. You write the other forty-nine because somebody, eventually, is going to hit them, and that somebody is going to be an accountant who cares very much about the answer.
Data Migrations That Survive Old Data
Every serious software project eventually needs to migrate data. A new field is added. An old field changes meaning. A parent-child relationship is restructured. The invisible work is making the migration survive data that has been accumulating for years under slightly different assumptions.
We recently migrated a warehouse-management customer off a misconfigured account structure that had been accumulating errors since they went live in mid-2025. Every warehouse was posting to a single catch-all account instead of its own. The fix involved rebuilding 3,600 historical stock transactions to post against the correct accounts, in batches over several hours, against closed accounting periods that had to be temporarily reopened, in a specific order, without disturbing any of the manual journal entries the accountant had been posting to adjust around the problem.
Invisible work, because the end state looks like it should have been like that from the start. No screen is different. No feature list changed. But the stock accounts now reconcile to the underlying stock movements exactly, month on month. And they will continue to, because the rebuild was written to handle the orphaned data, the gaps in batch tracking that came from the original migration, and the double-counting bug that had been quietly inflating the opening balances, all of which existed in the real data.
Useful Error Messages, Not Generic Ones
When code that runs in production catches an error, it has two choices. The useful choice is to catch the specific kind of error it expected, record it in a way that a future engineer can understand, and either recover or stop with a clear message. The useless choice is to catch everything, swallow it silently, and log “something went wrong.”
The useless choice is enormously tempting because it makes the immediate problem go away. The code no longer crashes. The user does not see a scary error. Shipping has happened. Six months later, the integration is failing silently and nobody will notice for weeks.
We recently debugged a food manufacturer’s order sync where the root cause was a single typo in a settings name, hidden inside one of those silent error handlers. Months of orders had been re-fetched every hour while four real, paid orders had never made it into the ERP. If the error handler had logged “failed to save the last-sync timestamp: the settings record this is being saved to does not exist”, somebody would have spotted it within the first week.
Logging the right thing is cheap. Silent error handlers are one of the most expensive things in a system.
Audit Trails
Financial software without an audit trail is not financial software. It is a spreadsheet with better validation.
Every financial action we build (every Xero push, every payment reconciliation, every rebuild of stock values, every tax calculation, every period close) writes a line to an audit trail. This is a separate concept from an error log. It records what happened, in what order, against which documents, with what outcome, and who was responsible. When an accountant calls us three months later with a question about why a payment was allocated the way it was, we can answer from the trail.
Audit trails are invisible work because they are never the feature. They are infrastructure. But they are the difference between answering a support question in five minutes and answering it after five hours of forensic work, or not being able to answer it at all.
Data That Stays Consistent When Things Go Wrong
The quietest kind of invisible work is making sure the data stays consistent when something does go wrong.
Operations that produce the same result whether they are run once or three times, so retrying them after a hiccup does no harm. All-or-nothing operations that never leave the system in a half-done state. Safeguards that stop two people accidentally doing the same one-time action at the same time. Background work that can be interrupted at any point and, on retry, picks up cleanly.
We build integrations where the truth of “did this actually succeed” is decided by the remote system, not by a flag we set locally. We build reconciliation routines that repair drift quietly rather than panicking about it. We build background work that can crash at any point and, on retry, does no harm. This is not glamorous work. It is the kind of work that means your system is still correct on a Monday morning after a Sunday night outage that nobody noticed.
Why Teams Skip It
The incentives are bad. Visible work gets budget. Invisible work does not. A feature list has customer-visible items; a test suite is not on the list. A contract specifies “build X”; it does not specify “X has to survive a server crash at 3am.”
Teams that skip the invisible work ship faster in the first three months. They look more productive. They are more productive, in the sense of producing more visible output. The bill comes due later, and it comes due on somebody else’s watch.
Clients often do not notice the difference until they are a year in, which is far enough past the initial decision that it feels like bad luck rather than a bad choice. The original team has moved on to the next project. The maintenance team is picking up a system where every feature is separately 80% finished, but in aggregate the whole thing is 40% functional because the parts that should have tied everything together were never built.
The Honest Version of This
We do the invisible work because we have been on the receiving end of not doing it.
We have been the engineering team called to rescue an integration that had been “working” for a year. We have opened systems where the automated checks were three lines long and all three of them passed trivially. We have traced financial reconciliation errors back to error handlers that silently swallowed everything. We have seen data migrations that shipped on the assumption that the data would always be in the shape the developer imagined, rather than the shape it actually was.
Every one of these was fixable. None of them was cheap. And all of them were the result of decisions three years earlier to ship something that looked finished without the work that would keep it finished.
What This Looks Like for a Client
If you are engaging a software team, these are the questions we would ask, not for signalling, but because the answers tell you whether the system you are paying for will still be worth anything in eighteen months:
- What automated checks get written for this feature? You want an answer that includes edge cases, not just the happy path.
- What happens when this integration fails? You want an answer that describes logging, alerting, and recovery, not just “it’ll retry.”
- What’s the audit trail for this? If it is a financial feature and there is no audit trail, that is a problem.
- How does the data migration handle records that are already in odd states? If the answer is “what odd states?”, the team has not thought about it yet.
- If I asked you to ship this a month earlier, what would you cut? The honest answer names specific invisible work. The dishonest answer says “nothing, we’d just work harder.”
The Bottom Line
A software project that costs 30% more to build and lasts five times as long is not a more expensive project. It is a vastly cheaper one. The industry is full of platforms that were “done” in six months and had to be thrown away in year two. The ones still running in year five are the ones where somebody, quietly and unromantically, did the invisible work.
This is not perfectionism. It is not over-engineering. It is professional discipline, the same way a builder uses proper foundations because they know how buildings fail. We think of it the same way. It is the reason the software we build is still running years later, doing the thing it was built for, with the same reliability it had on day one.
About HighFlyer
HighFlyer is an Auckland-based technology company. We build custom software, AI systems, and integrations for New Zealand and Australian businesses. The software we build is the kind you do not have to think about after it ships, because the invisible work is already done.
See our custom software services, learn about our approach, or get in touch if you want to talk through what a properly-built system for your business would look like.
Tags
About the Author

Imesha Sudasingha
Co-founder & CTO
Imesha is the Co-founder & CTO at HighFlyer and a member of the Apache Software Foundation with 10+ years of experience across integration, cloud, and AI. He cares a lot about the invisible work that keeps real systems standing.
A monthly note for SME operators
On technology, AI, and digitalisation. One real story, two trends, and one quick win each issue.
Recent Posts
Categories
You May Also Like
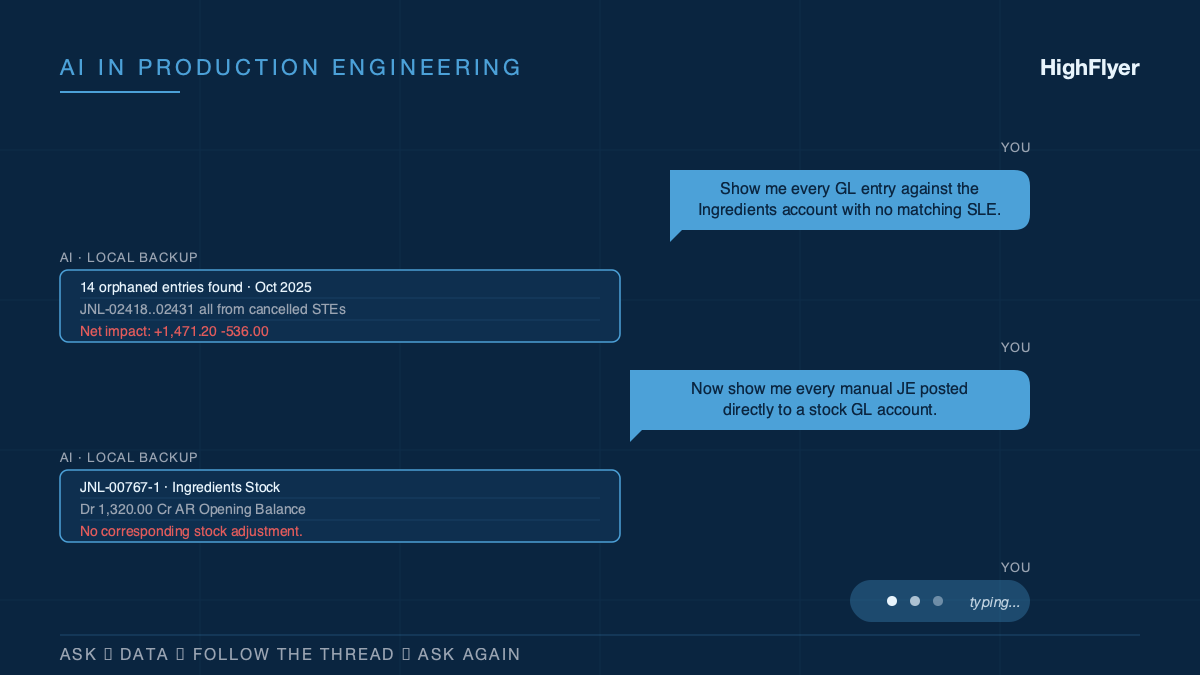
How We Actually Use AI on Real Customer Work
Eight months of unresolved accounting drift. 3,600 historical transactions. One working session to untangle it, because AI was sitting alongside...
Read More
From 3 Hours to 11 Seconds: Fixing a Shopify Stock Sync That Kept Timing Out
We kept bumping the timeout. First to 60 minutes. Then to 3 hours. It still timed out. The timeout was...
Read More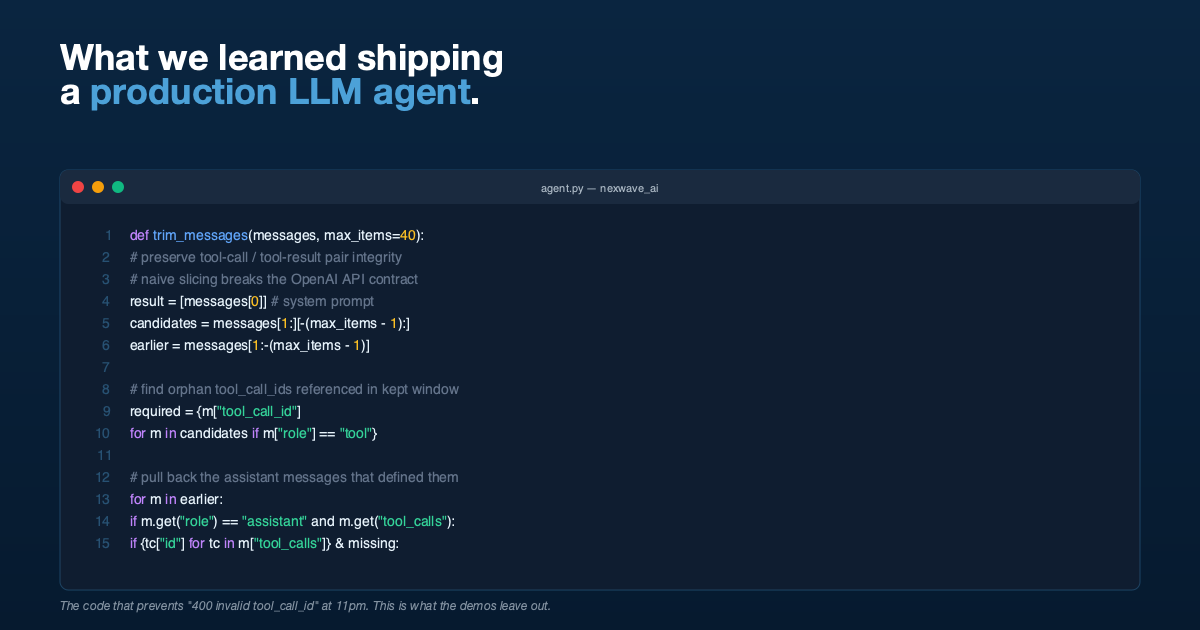
What We Learned Putting an AI Assistant Inside a Live Business System
An AI that gives a finance team an off-by-a-dollar answer loses their trust forever. Here are the five things we...
Read More